Estructuras Iterativas
Las instrucciones de repetición, de iteración o bucles, facilitan la repetición de un bloque de instrucciones, un número determinado de veces o mientras se cumpla una condición.
Por lo general, existen dos tipos de estructuras iterativas o bucles en los lenguajes de programación. Encontraremos un tipo de bucle que se ejecuta un número preestablecido de veces, que es controlado por un contador o índice, incrementado en cada iteración. Este tipo de bucle forma parte de la familia for.
Por otro lado, encontraremos un tipo de bucle que se ejecuta mientras se cumple una condición. Esta condición se comprueba al principio o el final de la construcción. Esta variante pertenece a la familia while or repeat, respectivamente.
Por último, siempre podemos consultar los comandos de control del flujo mediante ?Control en la consola de RStudio.
Bucle for
El bucle for es una estructura iterativa que se ejecuta un número preestablecido de veces, que es controlado por un contador o índice, incrementado en cada iteración.
A continuación, mostramos el diagrama de flujo del bucle for. En términos de diagramas de flujo, los rectángulos significan la realización de un proceso, en otras palabras la ejecución de un bloque de instrucciones. Por otro lado, los rombos con conocidos como símbolos de decisión, es decir se corresponden a preguntas cuyas respuestas únicamente tienen dos posibles respuestas, concretamente, TRUE (T) o FALSE (F).
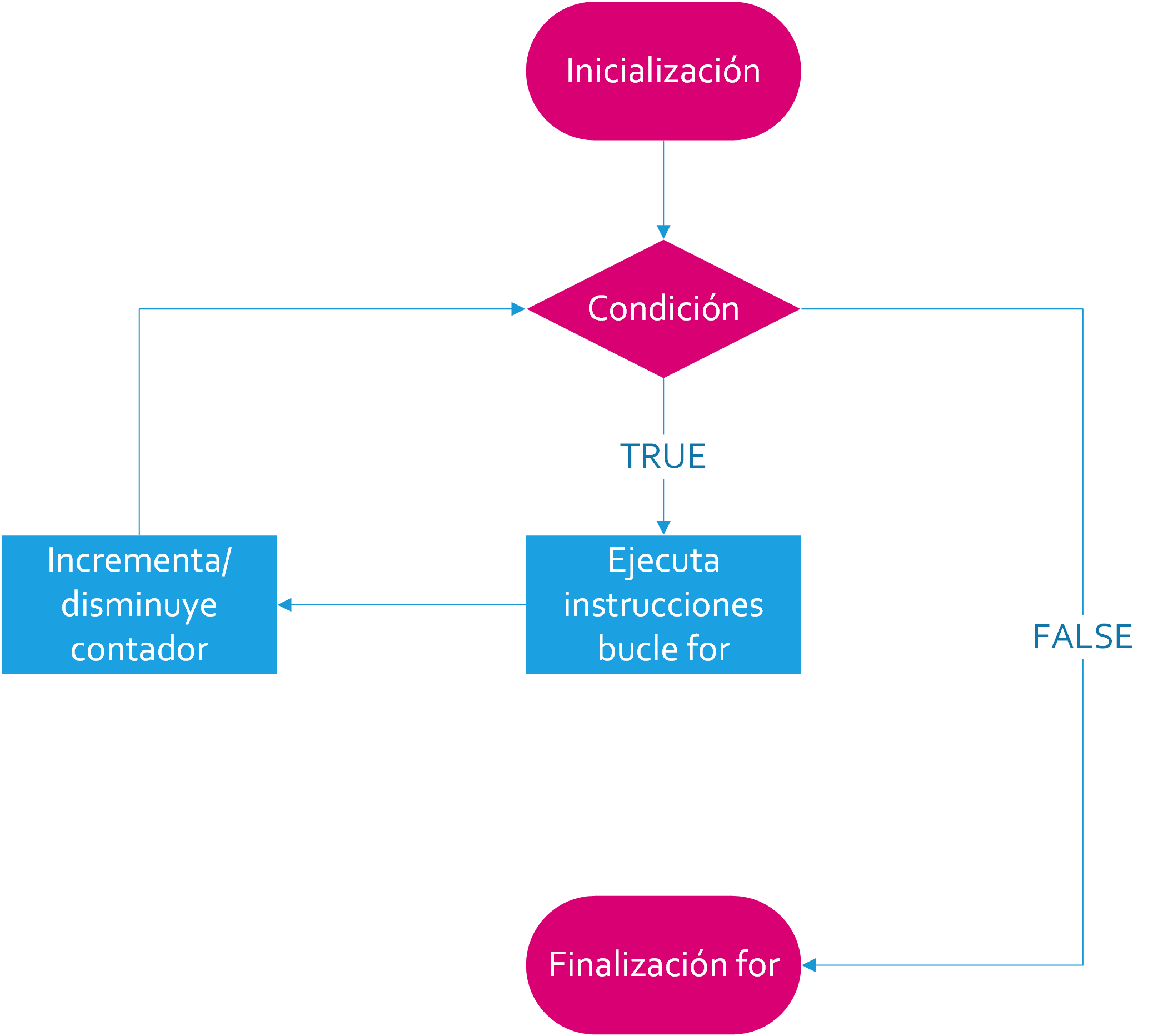
Una o mas instrucciones dentro del rectángulo de inicialización son seguidas por la evaluación de la condición en una variable la cual puede asumir valores dentro de una secuencia. En la figura, esto es representado por el símbolo del rombo.
En otras palabras, estamos comprobando si el valor actual de la variable está dentro de un rango específico. Por lo general, especificaremos el rango en la inicialización.
Si la condición no se cumple, es decir el resultado es False, el bucle nunca se ejecutará. Esto es indicado por la flecha de la derecha de la estructura for. El programa entonces ejecutará la primera instrucción que se encuentre después del bucle.
Si la condición se verifica, una instrucción o bloque de instrucciones es ejecutado. Una vez la ejecución de estas instrucciones ha finalizado, la condición es evaluada de nuevo. En la figura esto es indicado por las líneas que van desde el rectángulo que incrementa o disminuye el contador hasta el símbolo del rombo que evalúa la condición.
Por ejemplo, en el siguiente fragmento de código calculamos la media de un conjunto de observaciones, que se obtiene dividiendo la suma de todas las observaciones por el número de individuos:
# Creamos un vector aleaotorio de 10 observaciones
observaciones <- sample(1:50, 100, replace = TRUE)
# Inicializamos `suma` de todas las observaciones
suma <- 0
# Creamos un bucle for que calcula la media
for (i in seq_along(observaciones)) {
suma <- observaciones[i] + suma
media <- suma/length(observaciones)
}
# Mostramos por pantalla la media
media
## [1] 25.99
Bucles for Anidados
Los bucles for pueden ser anidados. En el siguiente fragmento de código creamos un algoritmo que calcula la suma de dos matrices cuadradas:
# Creamos dos matrices cuadradas
m1 <- matrix(sample(1:100, 9, replace = TRUE), nrow = 3)
m2 <- matrix(sample(1:100, 9, replace = TRUE), nrow = 3)
# Inicializamos la matriz que contendra m1+m2
suma <- matrix(nrow = 3, ncol = 3)
# Para cada fila y cada columna, realizamos la suma elemento a elemento
for (i in 1:nrow(m1)) {
for (j in 1:ncol(m1)) {
suma[i, j] <- m1[i, j] + m2[i, j]
}
}
# Mostramos por pantalla la suma de m1+m2
suma
## [,1] [,2] [,3]
## [1,] 113 162 42
## [2,] 143 90 146
## [3,] 119 109 110
El siguiente ejemplo sirve para ejemplificar el anidamiento de bucles for. Cada uno con su propio bloque de instrucciones y manejado con su propio índice. Es decir, i controla las filas de las matrices y j las columnas.
Bucle while
Cuando nos encontramos en la situación en la que no conocemos el número de iteraciones de antemano, podemos hacer uso del bucle while. Este bucle se ejecuta mientras se cumple una condición que se comprueba al principio de la construcción.
A continuación se muestra el diagrama de flujo de while:
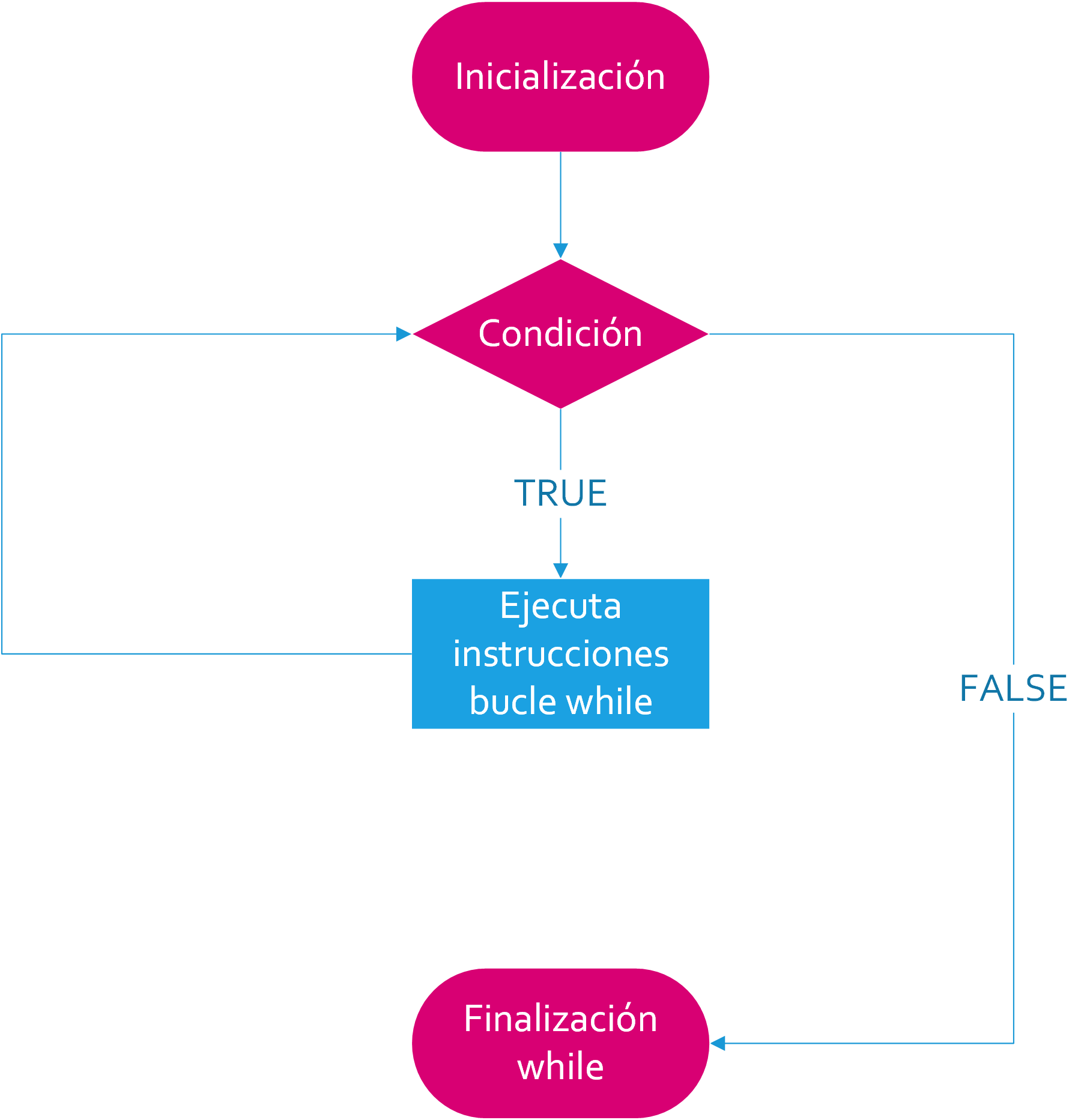
La estructura de una construcción while está compuesta de un bloque de inicialización, seguido por una condición lógica. Esta condición es normalmente una expresión de comparación entre una variable de control y un valor, en la que usaremos los operadores de comparación, pero cabe señalar que cualquier expresión que evalúa a un valor lógico, TRUE o FALSE, es válida.
Si el resultado es FALSE (F), el bucle nunca será ejecutado. Esto es indicado por la flecha de la derecha en la figura. En esta situación el programa ejecutará la primera instrucción que encuentre después del bloque iterativo.
Por otro lado, si el resultado es TRUE (T), la instrucción o bloque de instrucciones del cuerpo de while son ejecutadas. Esto sucederá hasta que la condición lógica sea FALSE.
El siguiente ejemplo es un ejemplo de utilización de la estructura while:
# Algoritmo que muestra por pantalla los 10 primeros números naturales
n = 1
while (n <= 5) {
print(n)
n = n + 1
}
## [1] 1
## [1] 2
## [1] 3
## [1] 4
## [1] 5
Bucle repeat
El bucle repeat es similar a while, excepto que la instrucción o bloque de instrucciones de repeat es ejecutado al menos una vez, sin importar cual es el resultado de la condición.
A continuación, como en los apartados anteriores mostramos el diagrama de flujo de la estructura repeat:
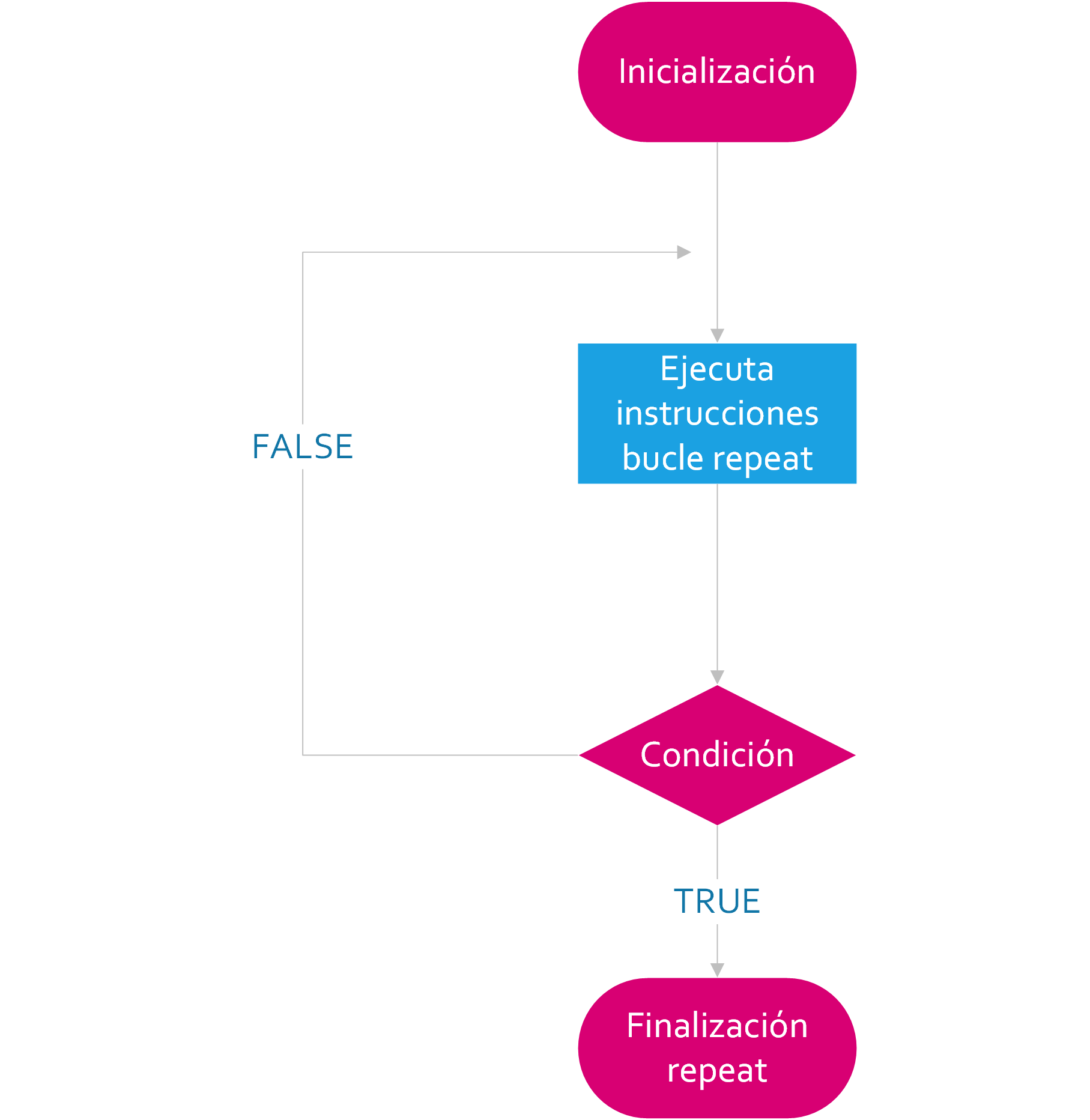
Como alternativa al ejemplo anterior, podríamos codificar el algoritmo como:
# Algoritmo que muestra por pantalla los 10 primeros números naturales
n = 1
repeat {
if (n <= 10) {
print(n)
n = n + 1
} else {
break
}
}
## [1] 1
## [1] 2
## [1] 3
## [1] 4
## [1] 5
## [1] 6
## [1] 7
## [1] 8
## [1] 9
## [1] 10
En el ejemplo de la estructura repeat podemos observar que el bloque de código es ejecutado al menos una vez y que finaliza cuando la función if es verificada.
Observemos que hemos tenido que establecer una condición dentro del bucle la cual establece la salida con la cláusula break. Esta cláusula nos introduce en el concepto de salida de las iteraciones en los bucles y que pasamos a analizar en el apartado siguiente.
Cláusula break
La instrucción break se utiliza con las instrucciones de bucle for, while y repeat.
La cláusula break finaliza la ejecución del bucle más próximo en el que aparece. El control pasa a la instrucción que hay a continuación del final de la instrucción, si hay alguna.
A continuación se muestra el diagrama de flujo de break:
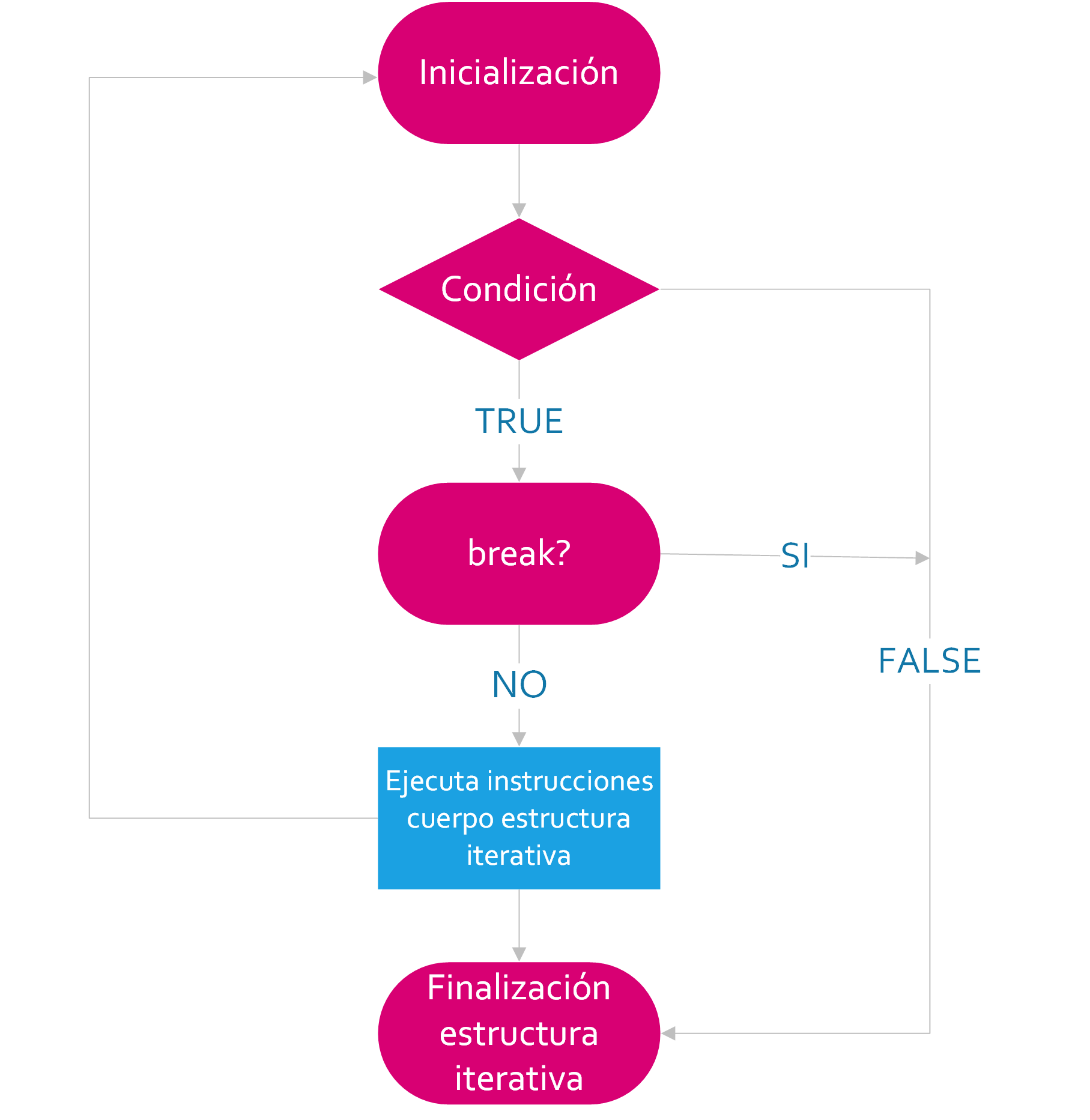
Como podemos ver en el diagrama de flujo, la instrucción break finaliza la ejecución de la instrucción envolvente for, while o repeat mas próxima. El control pasa a la instrucción que hay a continuación de la instrucción finalizada, si hay alguna.
Para ilustrar mejor el uso de break crearemos un algoritmo que define una matriz cuadrada y que utiliza dos bucles for anidados para calcular la diagonal principal y su matriz triangular superior:
# Creamos una matriz cuadrada de 6 x 6
m <- matrix(data = sample(x = 10, size = 36, replace = TRUE), nrow = 6, ncol = 6)
# Mostramos por pantalla `m`
m
## [,1] [,2] [,3] [,4] [,5] [,6]
## [1,] 10 1 2 5 8 6
## [2,] 8 8 3 9 8 7
## [3,] 8 9 2 5 1 7
## [4,] 4 3 3 4 4 1
## [5,] 6 5 8 8 7 7
## [6,] 10 3 1 2 2 3
# Creamos un vector para la diagonal principal
diagonal_principal <- vector(mode = "integer", length = nrow(m))
diagonal_principal
## [1] 0 0 0 0 0 0
# Algoritmo que calcula la matriz triangular inferior y su diagonal
# principal
for (i in 1:nrow(m)) {
for (j in 1:ncol(m)) {
if (i == j) {
break
} else {
m[i, j] <- 0
}
}
diagonal_principal[j] <- m[i, j]
}
# Mostramos por pantalla diagonal principal
diagonal_principal
## [1] 10 8 2 4 7 3
# Mostraamos por pantalla matriz inferior de m
m
## [,1] [,2] [,3] [,4] [,5] [,6]
## [1,] 10 1 2 5 8 6
## [2,] 0 8 3 9 8 7
## [3,] 0 0 2 5 1 7
## [4,] 0 0 0 4 4 1
## [5,] 0 0 0 0 7 7
## [6,] 0 0 0 0 0 3
Examinaremos brevemente ahora el código anterior, como se puede observar en primer lugar se define una matriz cuadrada de 6 x 6 y creamos un vector de tipo entero con una longitud de 6 que en el momento de su inicialización contiene todos sus valores igual a cero.
Cuando los indices son iguales cumpliéndose la condición del bucle for mas interno, y que itera mediante j por las columnas de la matriz, se ejecuta un break y el loop mas interno es interrumpido para saltar directamente a la instrucción del bucle mas externo. Esta instrucción calcula la diagonal principal de la matriz. Seguidamente, el control pasa la condición lógica del bucle más externo que itera por las filas de m mediante el índice i.
En el caso de que los indices sean diferentes, a la posición del elemento [i, j] se le asigna el valor de cero con el propósito de calcular la matriz triangula superior.
Por otro lado, dentro de instrucciones anidadas, la instrucción break finaliza solo la instrucción for, while o repeat que la envuelve inmediatamente. Podemos utilizar la instrucción next para transferir el control desde estructuras más anidadas. Esta cláusula nos introduce en el concepto de interrupción de las iteraciones en una estructura iterativa y que pasamos a analizar en el apartado siguiente.
Cláusula next
La cláusula next interrumpe una iteración y salta al siguiente ciclo. De hecho, salta a la evaluación de la condición del bucle en el que se encuentra.
En otros lenguajes de programación el equivalente a next es conocido como continue, cuyo significado es el mismo: en la línea de código que te encuentres, bajo la verificación de la condición, salta a la evaluación del bucle.
El diagrama de flujo de break se muestra en la figura siguiente:
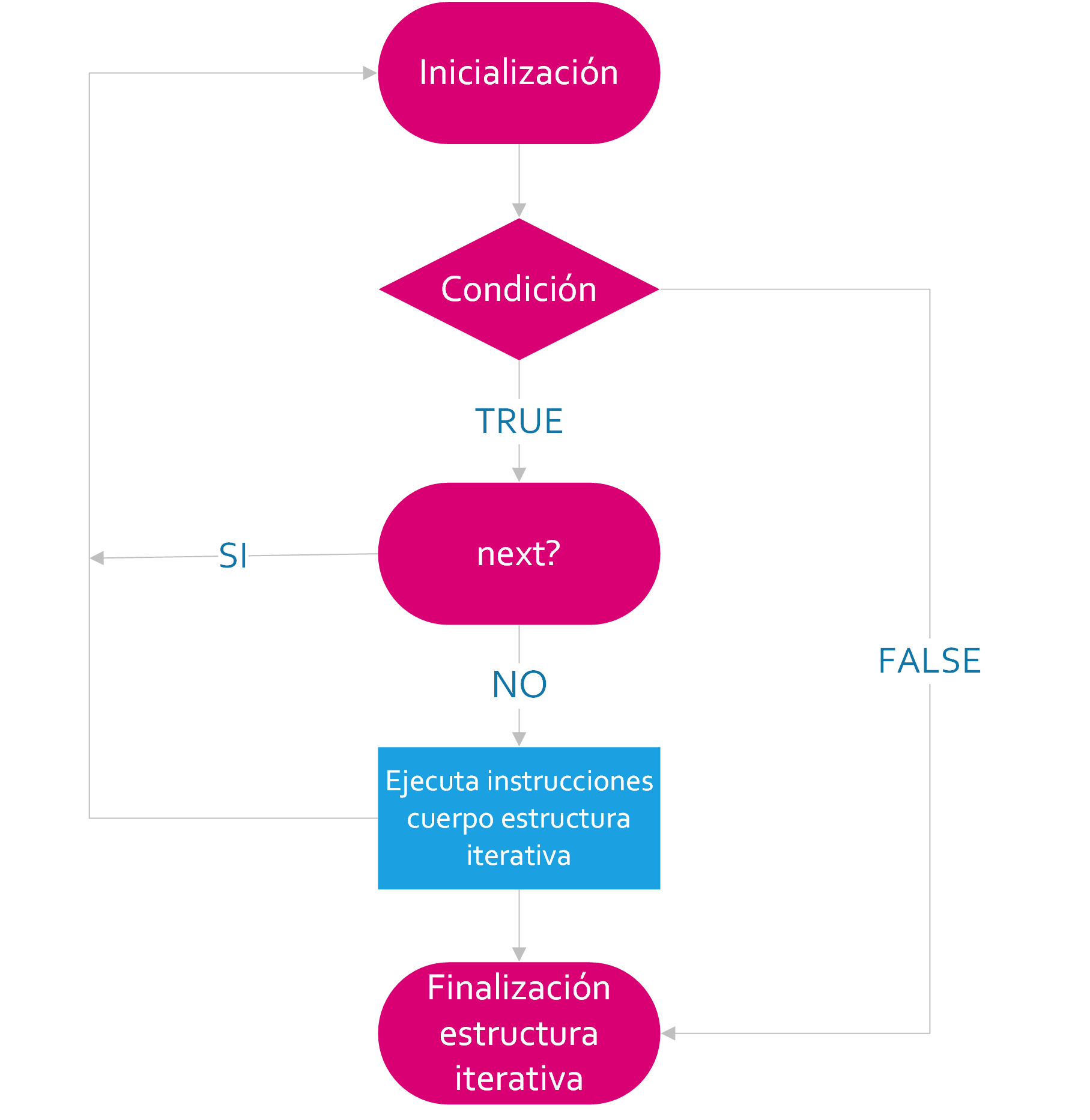
Examinemos a continuación el diagrama de flujo de la instrucción break.
Como hemos comentado con anterioridad break fuerza la transferencia del control a la expresión de control del bucle contenedor for, while o repeat más pequeño. Es decir, no se ejecuta ninguna de las instrucciones restantes de la iteración actual. La siguiente iteración del bucle se determina del modo siguiente:
En un bucle
whileorepeat, la siguiente iteración se inicia reevaluando la expresión de control de la instrucciónwhileorepeat.En un bucle
for, en primer lugar se incrementa el índice del bucle. A continuación, se evalúa de nuevo la expresión de control de la instrucciónfory, en función del resultado, el bucle finaliza o se produce otra iteración.
Pongamos por caso que queremos mostrar por pantalla los números pares de una secuencia de enteros:
for (i in 1:10) {
if (i%%2)
next
print(i)
}
## [1] 2
## [1] 4
## [1] 6
## [1] 8
## [1] 10
Este algoritmo utiliza el teorema del resto para calcular si un número es par o impar. Si el resto de dividir el número entre dos es igual a cero entonces se trata de un número par y es mostrado por pantalla.
Por otro lado, si el resto es diferente a cero será impar y saltará a la evaluación de la condición del bucle for ignorando cualquier instrucción que se encuentre a continuación.
Hay que mencionar, además el uso del operador %% para calcular el resto de la división especificado en la condición lógica de la instrucción if.
Alternativas al Uso de Bucles en R
Hasta el momento hemos visto el uso de bucles en R, pero podemos estar preguntándonos,¿Cuando usar los bucles en R y cuando no?
Como regla general, si nos encontramos en la situación que tenemos que llevar a cabo una tarea que requiere tres o mas repeticiones, entonces una instrucción iterativa puede ser útil. Esto hace que nuestro código sea mas compacto, legible y mas fácil de mantener.
Sin embargo, la peculiar naturaleza de R sugiere no hacer uso de los bucles en todas las situaciones cuandos exiten otras alternativas. R dispone de una característica que otros lenguajes de programación no disponen, que es conocida como vectorización y que ya hemos visto con anterioridad.
Además, puesto que R soporta el paradigma de programación funcional exiten la posibilidad de hacer uso de funciones en lugar de construcciones imperativas que hemos visto en esta sección y d la vectorización.
Este conjunto de funciones pertenecen la familia de funciones apply y las del paquete purr.
Vectorización
Como ya hemos visto con anterioridad, la vectorización nos permite realizar operaciones elemento a elemento en vectores y matrices.
Además, deberíamos saber a estas alturas que la estructura de datos elemental en R es el vector. Así pues, una colección de números es un vector numérico.
Si combinamos dos vectores de la misma longitud, obtenemos una matriz. Que como ya hemos visto podemos hacerlo vertical u horizontalmente, mediante el uso de diferentes instrucciones R. Es por eso, que en R una matriz es considerada como una colección de vectores verticales o horizontales. Lo dicho hasta aquí supone que, podemos vectorizar operaciones repetitivas en vectores.
De ahí que, la mayoría de las construcciones iterativas que hemos visto en los ejemplos de esta sección pueden realizarse en R por medio de la vectorización.
Sirva de ejemplo la suma de dos vectores v1 y v1 en un vector v3, la cual puede realizarse elemento a elemento mediante un bucle for como:
n <- 4
v1 <- c(1, 2, 3, 4)
v2 <- c(5, 6, 7, 8)
v3 <- vector(mode = "integer", length = length(n))
for (i in 1:n) {
v3[i] <- v1[i] + v2[i]
}
v3
## [1] 6 8 10 12
Si bien, podemos usar como alternativa la vectorización nativa de R:
v3 = v1 + v2
v3
## [1] 6 8 10 12
El Conjunto de Funciones apply
La familia apply pertenece al paquete base R y esta formado por un conjunto de funciones que nos permiten manipular una selección de elementos en matrices, arrays, listas y dataframes de forma repetitiva.
Es decir, estas funciones nos permiten iterar por los elementos sin tener la necesidad de utilizar explícitamente una construcción iterativa. Estas funciones toman como entrada una lista, matriz o array y aplican esta función a cada elemento. Esta función podría ser una función de agregación, como por ejemplo la media, u otra función de transformación o selección.
La familia apply esta compuesta de las funciones:
El paquete purrr
El paquete purr forma parte del ecosistema tidyverse y esta compuesto de un conjunto de funciones que aprovechan el paradigma de programación funcional de R, proporcionando un conjunto completo y consistente de herramientas para trabajar con funciones en listas y vectores.
Instalación
# La manera mas facil de conseguir `purrr` es instalar el ecosistema
# tidyverse
install.packages("tidyverse")
# Alternativamente, podemos instalar solo purrr:
install.packages("purrr")
El patrón de iterar por un vector, realizando una operación en cada elemento y calcular el resultado es tan común que el paquete purrr proporciona una familia de funciones para llevar a cabo esta tarea. Existe una función para cada tipo de salida:
- map() devuelve una lista.
- map_lgl() devuelve un vector lógico.
- map_int() devuelve un vector de enteros.
- map_dbl() devuelve un vector de reales.
- map_chr() devuelve un vector de tipo carácter.
Cada función toma un vector como entrada, aplica una función a cada elemento, y devuelve un vector de la misma longitud y con los mismos nombres de la entrada. El tipo de vector es determinado por el sufijo en la función map.
En este curso y en un módulo posterior, trataremos en profundidad el uso del paquete purrr que hace uso de la programación funcional en las iteraciones en oposición al paradigma de la iteración imperativa y que hemos tratado en este capítulo. Una vez dominemos las funciones en el paquete purrr, seremos capaces de resolver la gran mayoría de algoritmos que impliquen la iteración con menos código, mas legible y con menos errores.
Uso
El siguiente ejemplo sirve para demostrar las diferentes alternativas que disponemos para realizar un algoritmo iterativo mediante las herramientas que hemos visto en este capítulo.
Consideremos que queremos calcular el cuadrado de cada elemento en una secuencia de enteros del 1 a n. La primera solución pasa por utilizar una construcción iterativa:
n <- 5
res <- rep(NA_integer_, n)
for (i in seq_len(n)) {
res[i] <- i^2
}
res
## [1] 1 4 9 16 25
La segunda opción es por medio de la vectorización:
n <- 5
seq_len(n)^2
## [1] 1 4 9 16 25
En tercer lugar, mediante sapply:
n <- 5
sapply(1:n, function(x) x^2)
## [1] 1 4 9 16 25
Por último, mediante purrr::map():
n <- 5
map_dbl(1:n, function(x) x^2)
## [1] 1 4 9 16 25
En este ejemplo por la sencillez del caso las dos últimas alternativas no son necesarias y la correcta sería hacerlo mediante vectorización. Pero en estructuras de datos y funciones mas complejas optaríamos por cualquiera de las dos últimas opciones.
En este curso y en un módulo posterior, trataremos en profundidad el uso del paquete purrr que hace uso de la programación funcional en las iteraciones en oposición al paradigma de la iteración imperativa y que hemos tratado en este capítulo. Una vez dominemos las funciones en el paquete purrr, seremos capaces de resolver la gran mayoría de algoritmos que impliquen la iteración con menos código, mas legible y con menos errores.
Consejos para el uso de Bucles en R
Siempre que sea posible hemos de poner la menor cantidad de instrucciones dentro de una estructura iterativa. Puesto que, todas las instrucciones dentro de un bucle se repiten varios ciclos y quizás no sea necesario.
Hemos de tener cuidado con el uso de
repeat, asegurándonos que definimos de forma explícita una condición para finalizar la estructura, de lo contrario nos encontraremos ante una iteración infinita.Tratar de usar como alternativa a los bucles anidados la recursividad en funciones. Es decir, es mejor el uso de una o mas llamadas a funciones dentro del bucle a que este sea demasiado grande.
La peculiar naturaleza de R nos sugiere no usar las construcciones iterativas para todo, cuando disponemos de otras alternativas como la vectorización, la familia
applyy el paquetepurrr.